Live operations
Multi-feed GTFS-RT ingest, Redis-cached reads, WebSocket live push, PostGIS proximity search, TimescaleDB history.
vtv is a transit operations platform I designed and built solo: live vehicle tracking, scheduling, and an AI operations copilot for Latvia's public transport, starting with Riga's buses. This page shows the product, then the engineering underneath it (the agent system, memory, dispatch, and guardrails) in the terms I think matter to a CRM team.
Dispatchers run 14 routes and 187 vehicles from one screen. The copilot, Aīda, watches the same data they do: live GTFS-RT positions, driver hours, schedules, maintenance capacity, and the document base. It resolves what it safely can, and brings the rest to a human with a recommendation and its sources.
Multi-feed GTFS-RT ingest, Redis-cached reads, WebSocket live push, PostGIS proximity search, TimescaleDB history.
Aīda orchestrates four specialist Pydantic AI agents: 15 typed tools between them, server-side memory, deterministic QA on every answer.
Next.js 16 CMS with role-based access, bilingual throughout (Latvian / English), typed SDK generated from the API.
Eight views from the console, picked to show the range. The full product goes further: routes, stops, live map, schedules, drivers, fleet and telemetry, geofences, analytics, GTFS management, users, and documents (the sidebar in each screenshot lists the rest). Screens show the Latvian console with demonstration data; every view ships in Latvian and English. In each one the agent acts first, shows its sources, and asks before doing anything irreversible.
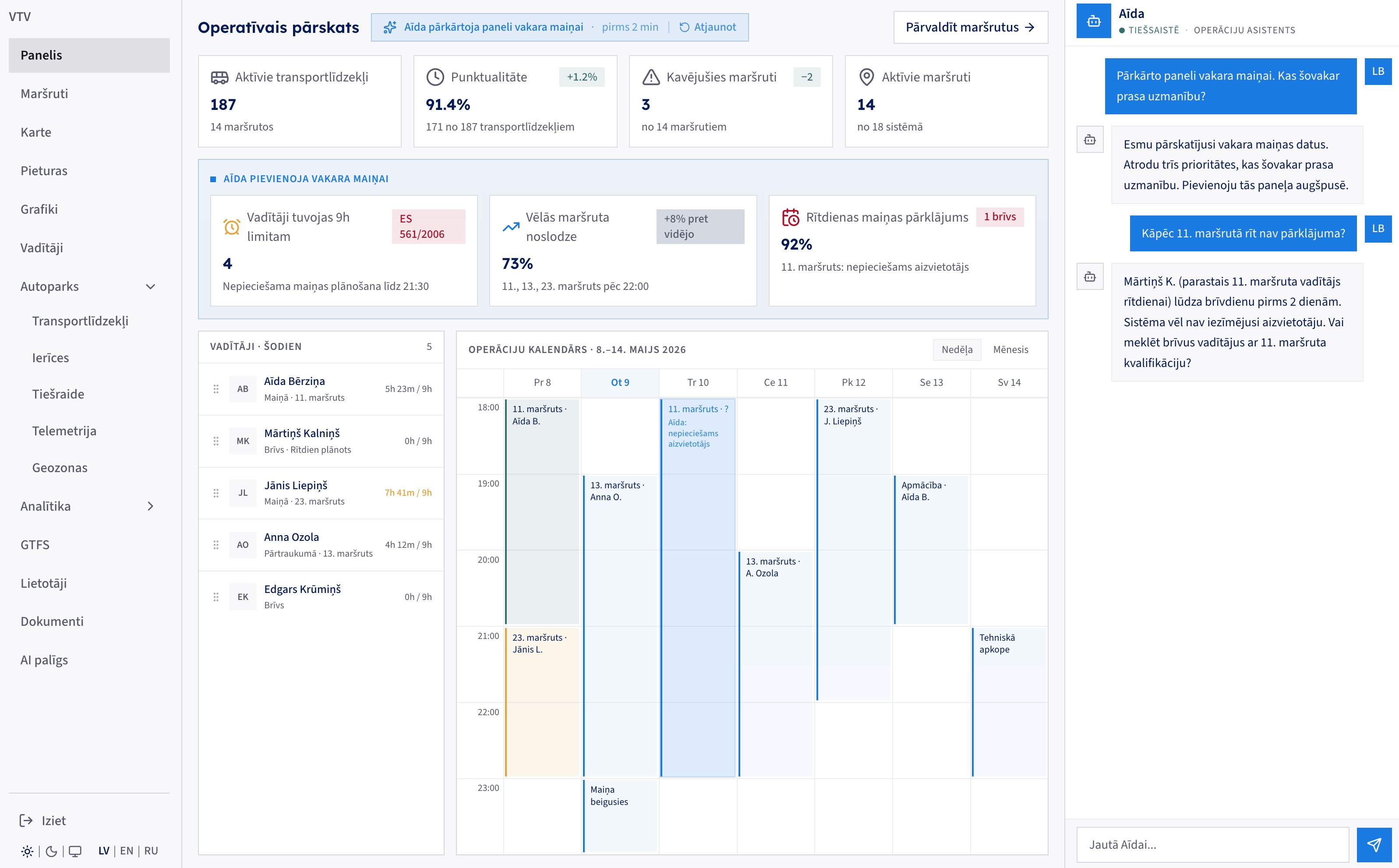
The dispatcher asked Aīda to reorganise the panel for the evening shift. It surfaced three priorities (drivers nearing the EU 9-hour limit, late-evening route load, tomorrow's uncovered shift) and pinned them above the roster and calendar. The conversation on the right is the audit trail.
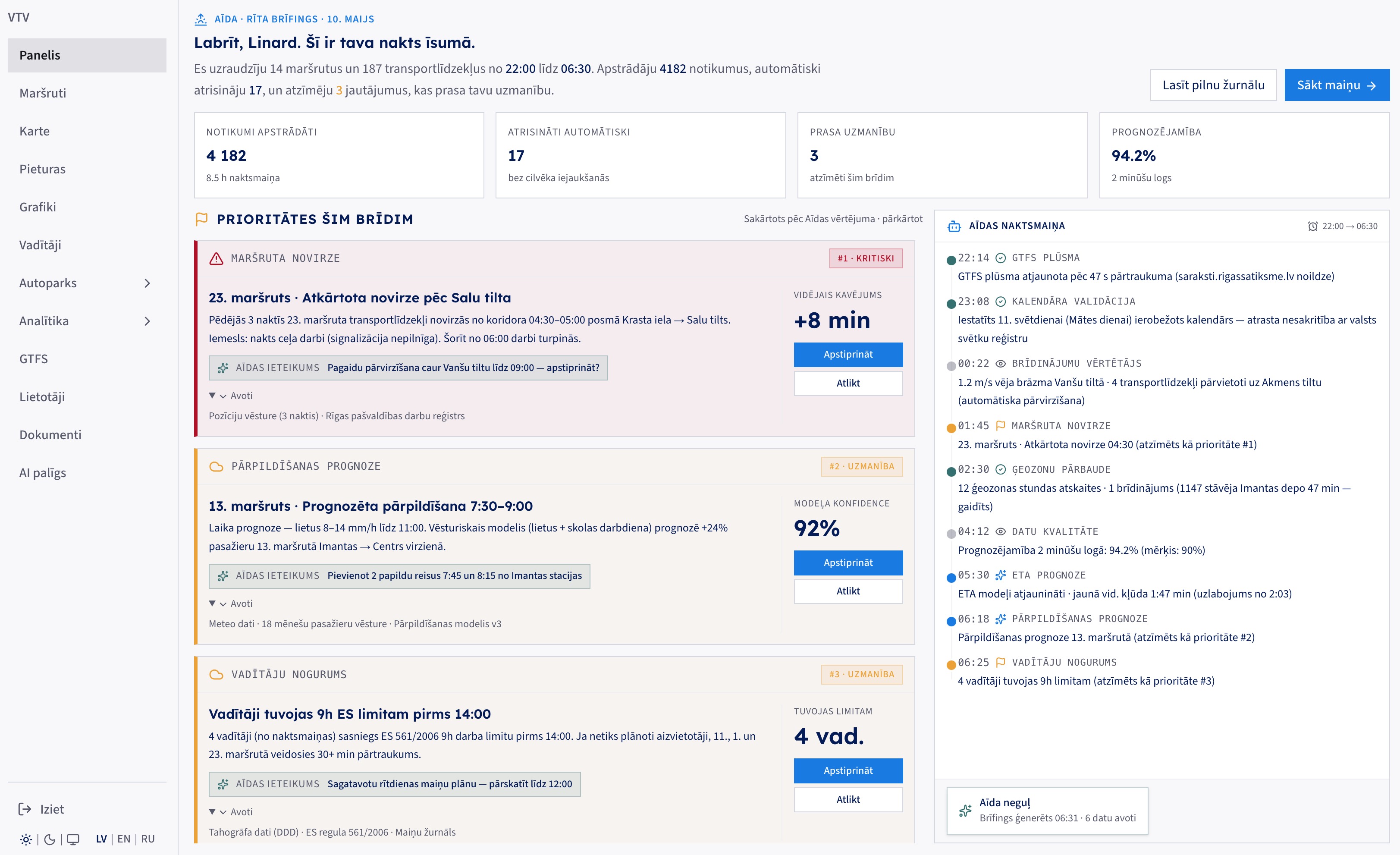
Overnight, the agent monitored every route unattended: 4,182 events processed, 17 resolved automatically, 3 flagged for a human. Each flagged item carries a recommendation, a confidence figure, and its sources. The night timeline on the right shows what happened while everyone slept. This is lifecycle messaging, applied to operations.
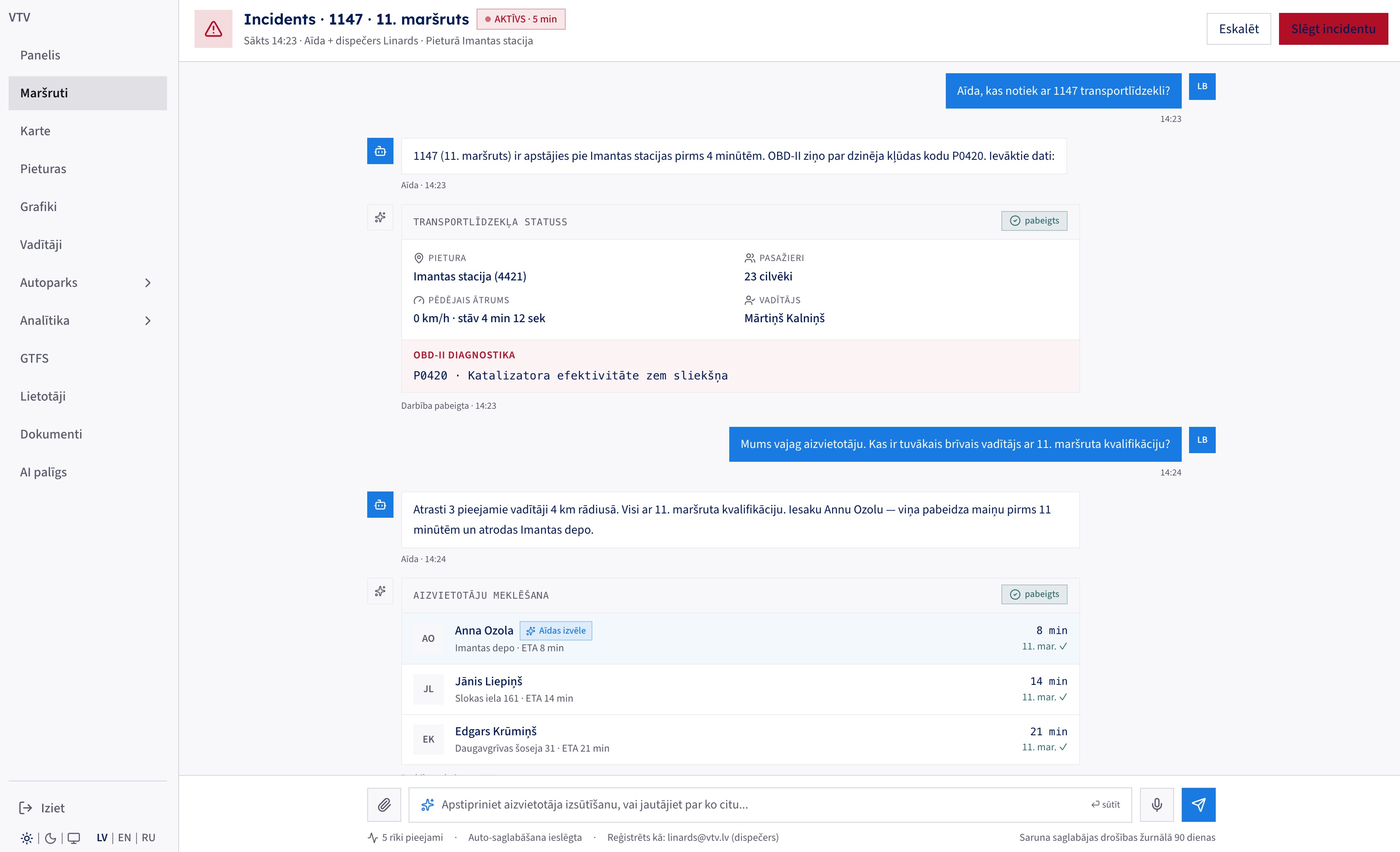
A bus stops with an engine fault. The dispatcher asks what happened; the agent pulls live telemetry and the OBD-II code, then finds three qualified replacement drivers within 4 km, ranks them by arrival time and remaining legal driving hours, and recommends one. The human confirms the dispatch, and the whole conversation stays in the audit log for 90 days.
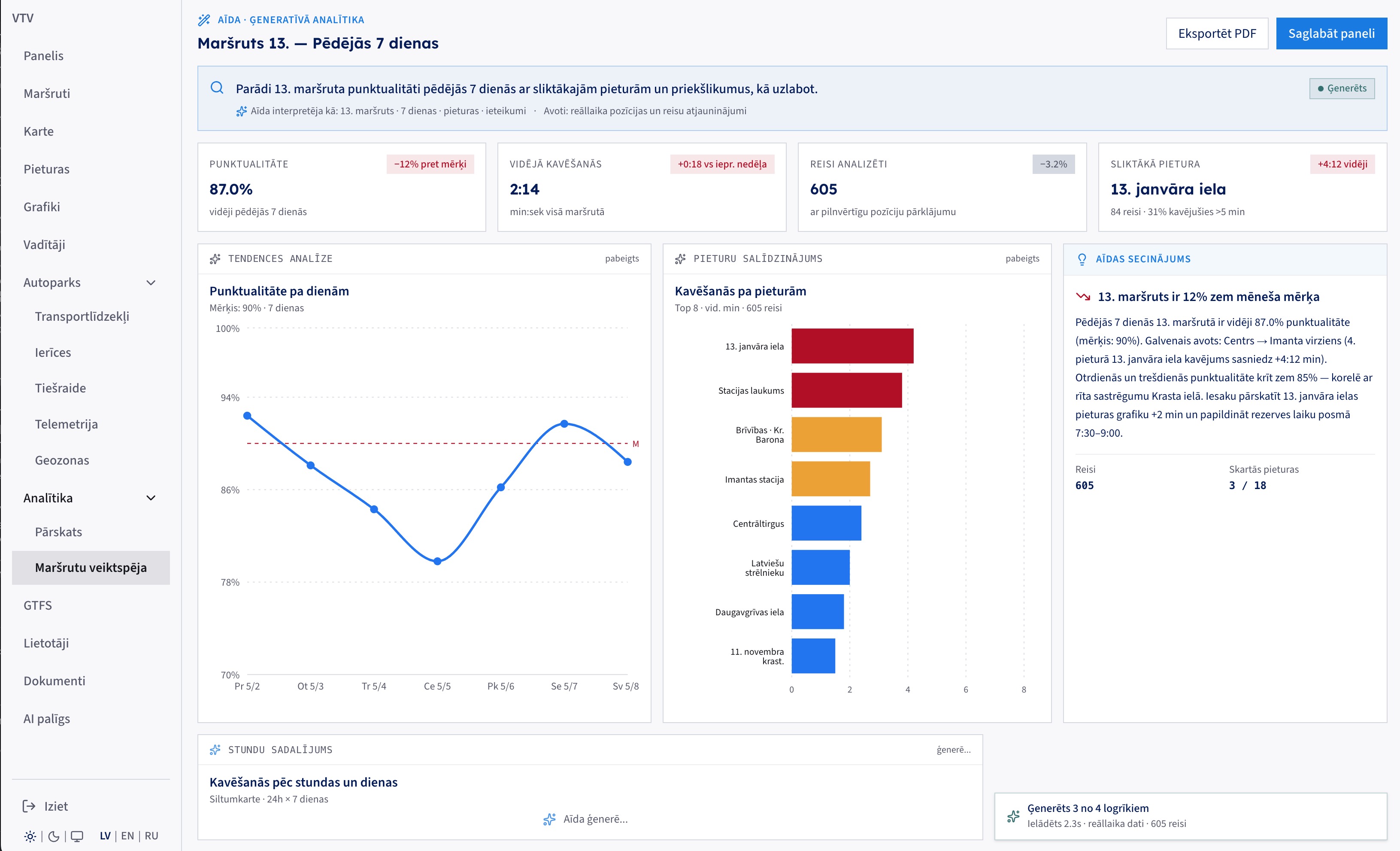
One plain-language question ("show route 13's punctuality for the last 7 days with the worst stops and how to improve") becomes a dashboard: trend against target, delay by stop, and a written conclusion with a concrete recommendation. The agent built it from 605 real trips in 2.3 seconds, and it exports to PDF.
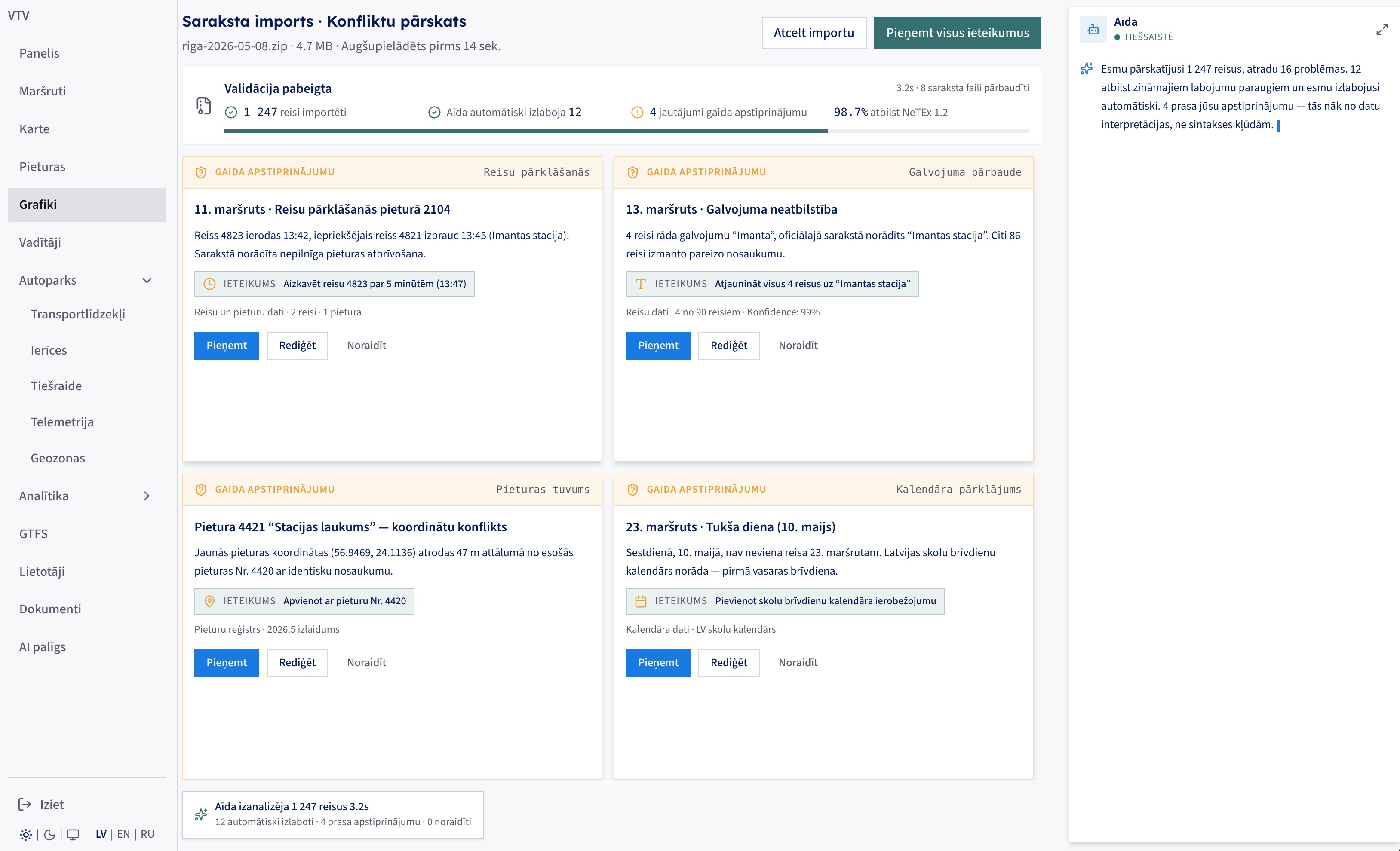
The importer validated 1,247 trips in 3.2 seconds, fixed twelve known-pattern issues on its own, and held four judgement calls for approval, each with a one-click recommendation. 98.7% NeTEx 1.2 conformant.
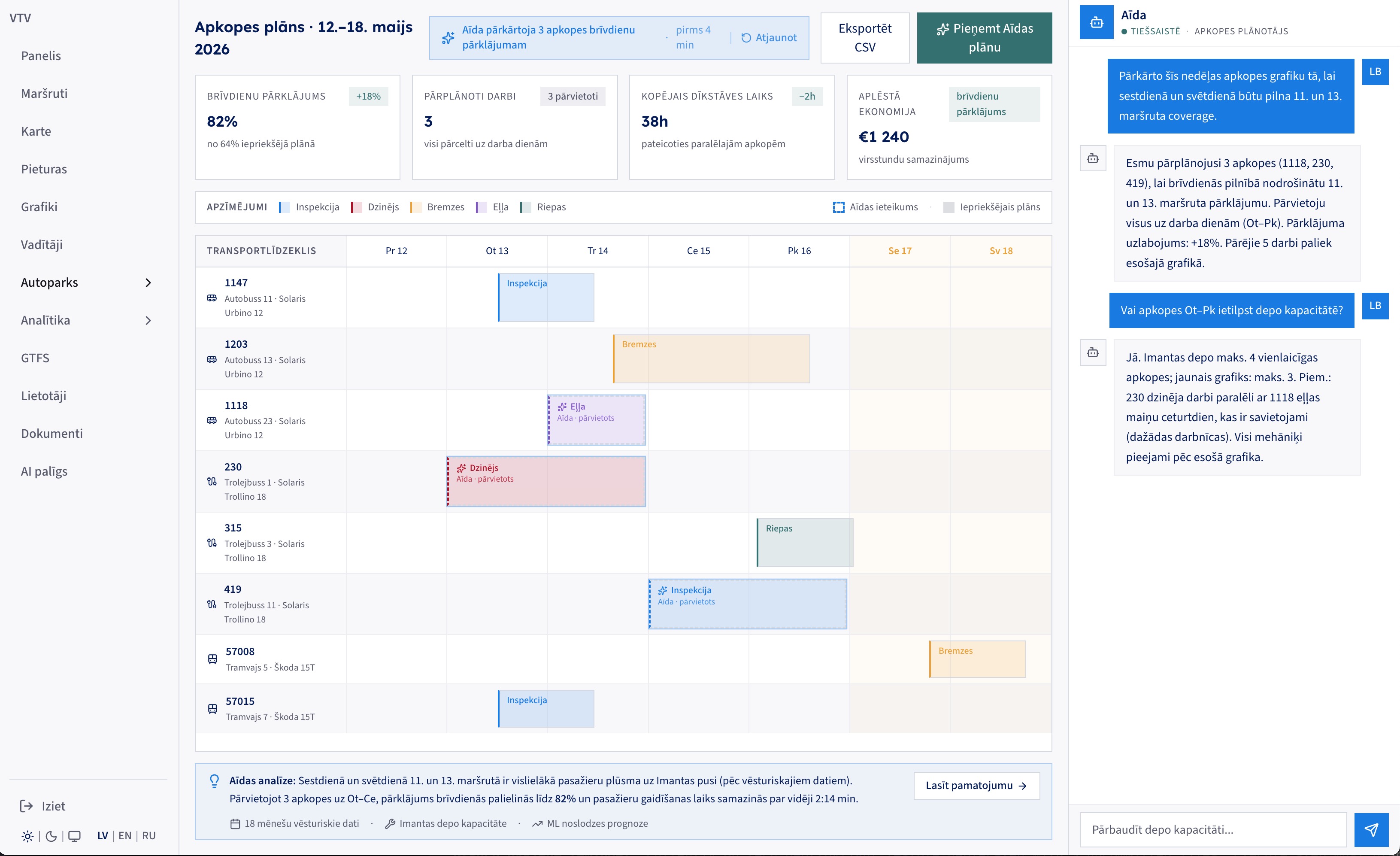
Asked to protect weekend coverage, the agent moved three maintenance jobs to weekdays, checked depot capacity, and quantified the result: +18 points of coverage, 38 hours less downtime, an estimated €1,240 saved.
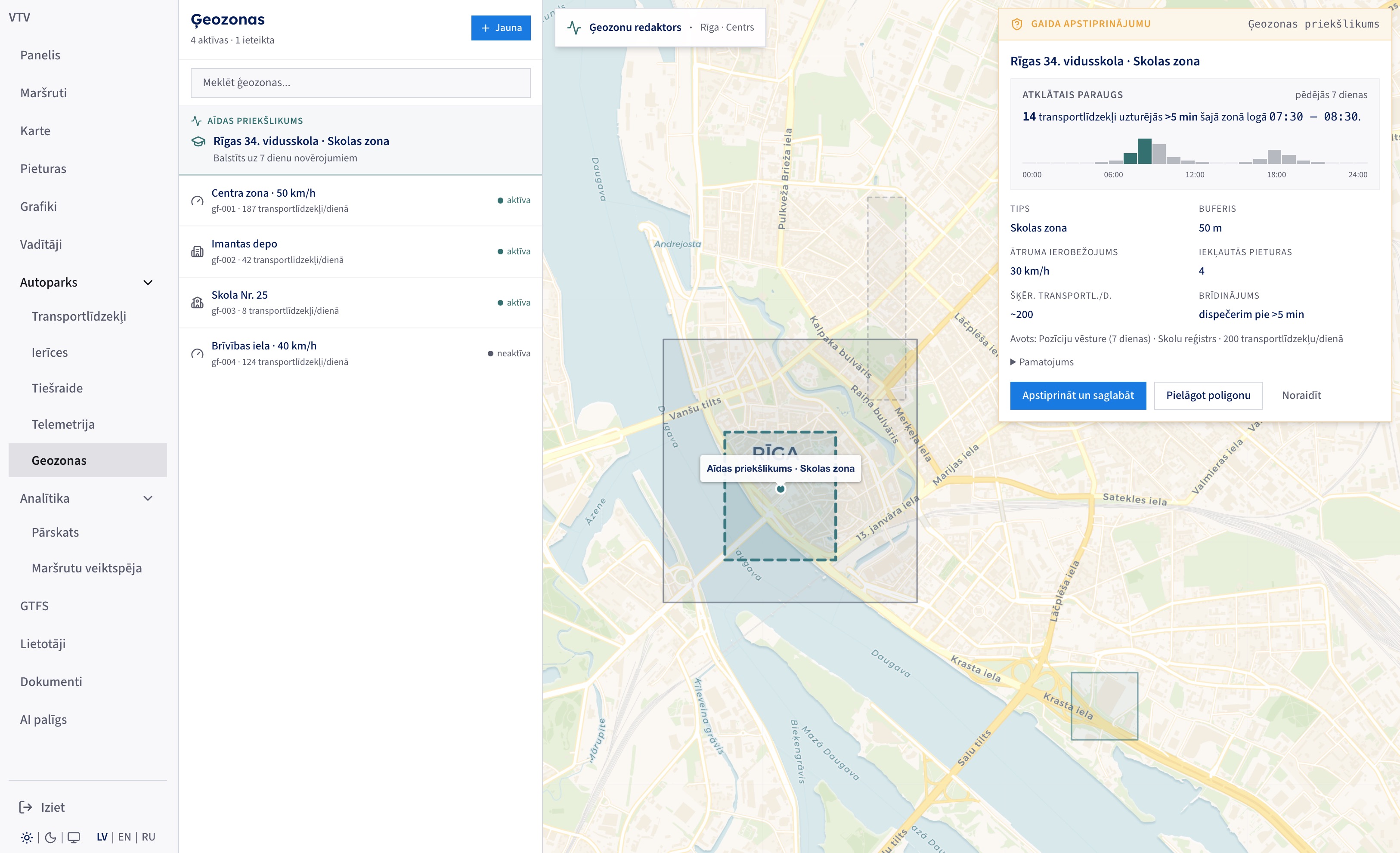
From seven days of movement data the agent noticed 14 vehicles dwelling near a school at peak hours and drafted a speed-limited school zone with the polygon, buffer, and alert rule already filled in. A human approves, adjusts, or rejects it.
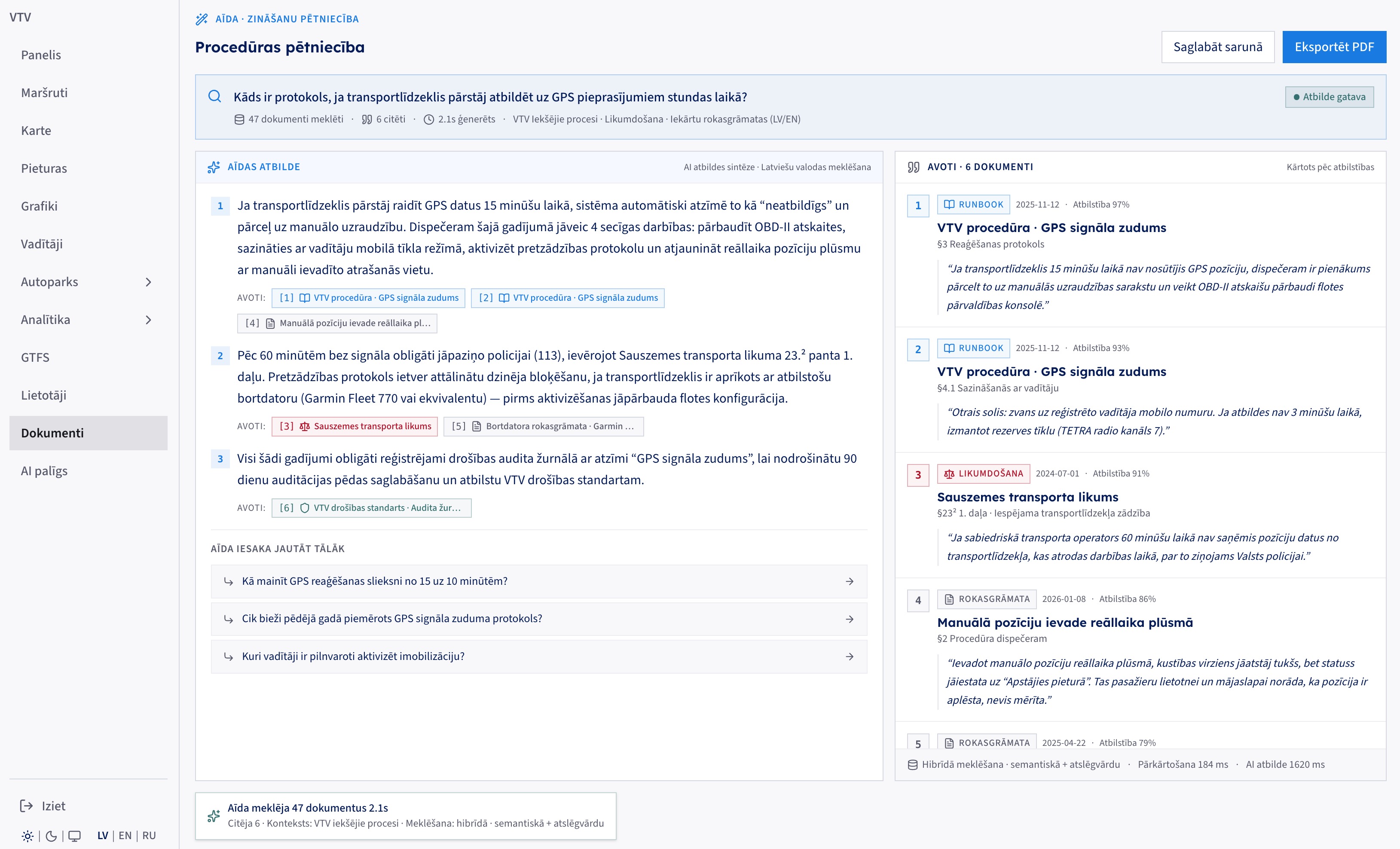
"What is the protocol when a vehicle stops answering GPS for an hour?" The agent answered from 47 internal documents and national legislation in 2.1 seconds, cited every claim to a specific section, and suggested three follow-up questions.
Read-only where it matters; destructive actions require explicit confirmation.
TransitAgent, KnowledgeAgent, VaultAgent, UnifiedAgent. Each can also be addressed directly.
Unit, agent, security, and end-to-end suites gate every push.
An LLM judge and committed baselines catch quality regressions in CI.
Prompt-injection detection inbound, exfiltration validation outbound.
Latvian and English end to end: UI, agents, guardrails, and evals.
Aīda is the front door. A heuristic domain router classifies every prompt in microseconds, without an LLM call, and hands it to the right specialist. People can also work with a specialist directly, and an explicit choice is never overridden by the router. A second router then picks a fast, standard, or complex model for the job, so cheap questions stay cheap.
Live operations: 9 transit tools, full deterministic QA, self-correction, and the complex-tier pipeline.
Document research over the RAG stack, with citations enforced in the prompt. Retrieval is always on.
Note and folder management: 4 read-write tools, dry-run previews, deletes gated behind explicit confirmation.
The all-tools fallback. Carries every tool, so existing clients and ambiguous prompts keep working.
Nine read-only transit tools (live status, timetables, adherence reports, driver availability, ML ETA and load prediction, intercity search), one RAG search tool, four vault tools with dry-run previews and confirm-gated deletes, one skills manager. The docstrings are written for the model as much as for the human reader, because they steer tool selection.
Inbound, prompt-injection detection over the OWASP LLM01 taxonomy: 31 compiled patterns across 6 categories, in English and Latvian, with Cyrillic-homoglyph normalisation and warn or block modes. Outbound, exfiltration validation that checks for base64 blobs, suspicious URLs, system-prompt leaks, and PII before any answer reaches a user.
Every answer passes rule-based checks: do the routes and stops exist, are the delays plausible, are timestamps consistent, is every citation grounded, does the reply language match the question. Error-severity failures trigger one bounded retry; low confidence re-routes once to the complex tier. Both are hard-capped, so a bad answer can never turn into an endless loop.
Per-provider three-state circuit breakers with sliding-window failure rates, a provider fallback chain, and a health tracker exposing p50/p95 latency per provider. When every provider is down, users get an honest static answer rather than a stack trace. The whole thing is LLM-agnostic: swapping models is a config change.
Markdown skill packs load into context by priority within per-agent token budgets: always-on procedures first, situational knowledge only when the prompt calls for it.
33 synthetic cases across the three domains, each graded by an LLM judge against five or six named criteria. Traces persist as JSONL, per-criterion pass rates form committed baselines, and any criterion dropping more than 3 points fails the build. A prompt change has to prove itself before it ships.
The copilot remembers. Server-side, with a lifecycle.
I built vtv for dispatchers, not marketers, but the engineering problems are the ones a CRM team lives with daily. Before this, I hand-coded multi-brand email campaigns as an email developer at Dentsu, so the messaging side isn't new to me either.
Thousands of events in, triage, one prioritised summary out, addressed to a named person at the moment they need it. That's a trigger-based campaign with an audience of one, and the pipeline generalises.
Every message is scored against signal sets and routed to the specialist that will handle it best, with a safe fallback. The same discipline as audience segmentation: cheap classification first, expensive handling only where it pays.
Traces, an independent judge, committed baselines, and a regression gate in CI. Swap "prompt change" for "subject-line change" and this is the A/B rigour CRM programmes need, especially as AI writes more of the copy.
1,247 records validated, safe fixes applied automatically, judgement calls held for a human with a recommendation attached. The same pattern keeps a CRM database clean without silently corrupting it.
Raw episodes compact into durable, queryable knowledge with decay, so recent behaviour weighs more than stale history. That is a single customer view, built from first principles.
Two languages run through the UI, the agents, the guardrail patterns, and the evals, rather than being bolted on afterwards. Trainline operates across markets; I've built for that constraint from day one.
Everything above runs today, and the full GitHub repository is available on request. I'm happy to walk through any layer of it live (the agent pipeline, the eval harness, the memory system) and talk about where that experience serves Trainline's CRM team, or whether it's not a fit.